
티스토리 뷰
반응형

데이터 리니지를 도입하려면 단순히 도구를 설치하는 것 이상으로 구조적인 구성 전략이 필요합니다.
이번 편에서는 실무 환경에서의 데이터 리니지 구성 방법을 단계별로 안내합니다.
리니지 구성의 큰 틀
데이터 리니지는 다음 세 가지 관점에서 구성됩니다.
| 계층 | 설명 |
| 수평 리니지 | 데이터 흐름 (source → staging → data mart → 모델/리포트) 추적 |
| 수직 리니지 | 하나의 테이블 내부에서 컬럼 단위 가공 흐름 추적 |
| 운영 리니지 | 데이터 처리 작업 간 트리거, 타이밍, 책임자 정보 포함 |
리니지 구성 단계별 가이드
✅ 1단계. 데이터 자산 식별
- 대상: 테이블, 파일, API, 로그, ML 모델, 리포트 등
- 메타데이터 자동 수집 필요
추천 도구: dbt, DataHub, OpenMetadata, Amundsen
✅ 2단계. 데이터 흐름 매핑 (ETL/ELT 파이프라인 추적)
| 도구 | 수집 방식 |
| Airflow | DAG 기반 자동 추적 (OpenLineage 연동) |
| dbt | dbt docs로 DAG 생성 가능 |
| Spark | Job DAG 추적, OpenLineage 연계 |
| Python 수작업 | 데코레이터 기반 로깅 직접 구현 |
✅ 3단계. 컬럼 단위 리니지 구성
- SQL 파싱 또는 dbt macro 활용
- 예시:
SELECT customer_id, SUM(price * quantity) AS total_spent FROM sales_data GROUP BY customer_id
→ total_spent 컬럼은 price, quantity 컬럼에서 유래됨
✅ 4단계. 리니지 시각화 및 검색
- 데이터 리니지는 "보여지는 것"이 중요
- DAG, 영향도 분석, 컬럼 트래킹 기능 필요
추천 도구
- DataHub: 유려한 시각화와 빠른 탐색
- OpenMetadata: AI metadata와 통합 용이
- Marquez: 리니지 전용 UI
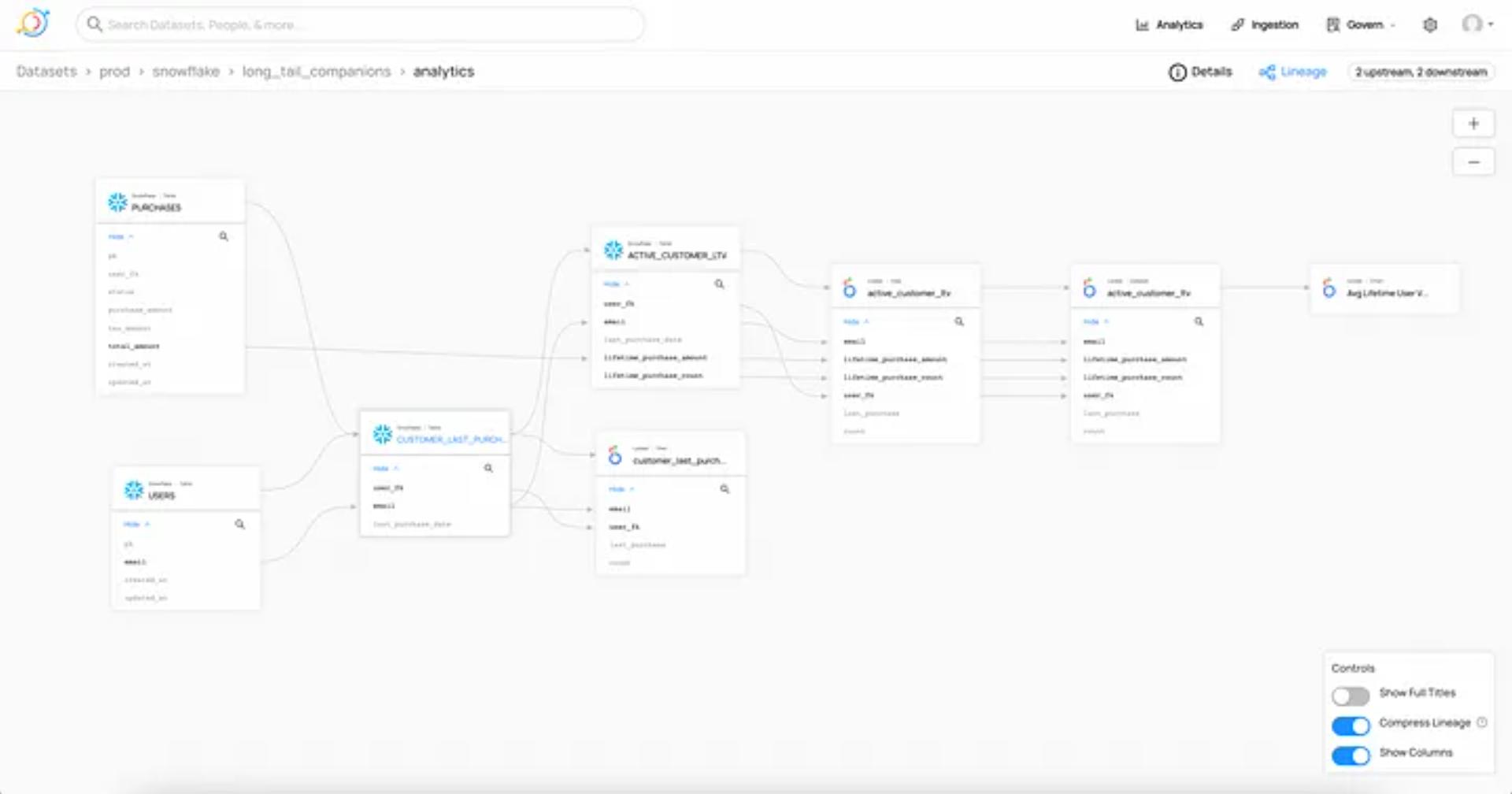
실무 예시: 리니지 도구 조합
| 목적 | 도구 조합 |
| dbt 기반 분석 | dbt + DataHub + Airflow + Snowflake |
| Spark 환경 | Spark + OpenLineage + Marquez |
| DW 환경 | Amundsen + Apache Atlas |
| AI 환경 | Feature Store + Feast + MLflow + DataHub |
마무리: 성공적인 리니지의 핵심
- 중요한 데이터 흐름부터 시작
- 개발자뿐 아니라 분석가 중심으로 구성
- 변화관리와 함께 도입
리니지는 도구가 아닌 전략입니다.
데이터를 신뢰받는 자산으로 만들고 싶다면, 리니지 구축은 더 이상 선택이 아닙니다.
[관련 포스트]
[데이터 리니지] 1. AI 시대, 데이터 리니지의 중요성
[데이터 리니지] 2. 분석계 데이터가 많아질수록 데이터 리니지가 필요한 이유
반응형
'IT Lab > Database' 카테고리의 다른 글
| [SQL] ANSI SQL vs PostgreSQL 문법 비교 (5) | 2025.08.24 |
|---|---|
| [데이터 엔지니어링] 최신 데이터 도구 업데이트 (2025년 8월) | Airflow·Snowflake·PostgreSQL·Iceberg (9) | 2025.08.16 |
| [데이터 리니지] 2. 분석계 데이터가 많아질수록 데이터 리니지가 필요한 이유 (0) | 2025.08.02 |
| [데이터 리니지] 1. AI 시대, 데이터 리니지의 중요성 (0) | 2025.08.02 |
| [DB 실무] DBeaver로 데이터베이스 간 테이블 복사하기 (1) | 2025.07.09 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
TAG
- 테이블복사
- 데이터 리니지
- 바이브코딩
- mssql
- ChatGPT
- Kubernetes
- PostgreSQL
- Agent Coding
- DBMS
- sqlserver
- 앱개발
- sql
- Xcode
- DATABASE
- AnsiSQL
- dockerswarm
- 엔터프라이즈ai
- 데이터리니지
- 에이전트코딩
- 컨테이너오케스트레이션
- 데이터베이스
- 데이터플랫폼
- DB
- java배포
- k8s
- db운영
- AX
- data lineage
- IOS
- AI페르소나
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
글 보관함